AutoFHE: Automated Adaption of CNNs for Efficient Evaluation over FHE

Wei Ao

Vishnu Boddeti
Philadelphia, PA, USA 2024Michigan State University
Secure deep learning under fully homomorprhic encryptionDeep Learning as a Service (DLaaS)

Internet
Prediction


Customer

Prediction
Prediction
Cloud


Secure DLaaS under Fully Homomorphic Encryption (FHE)
Prediction
Prediction
Customer
Cloud
Internet
1
Initiative: privacy homomorphisms, 1978
2
Gentry's Blueprint uses Ideal lattices, 2009
3
Approximate Arithmetic under leveled homomorphic encryption: CKKS (HEAAN), ASIACRYPT 2017
4
Bootstrapping for CKKS: fully homomorphic encryption, EUROCRYPT 2018
6
AutoFHE: Automated Adaption of CNNs for Efficient Evaluation over FHE, USENIX 2024
5
MPCNN: Deep CNNs on RNS-CKKS FHE scheme, ICML 2022
From Secure Computation to Secure Deep Learning
Convolutional Neural Networks (CNNs)

Prediction
Convolution
BatchNorm
ReLU
Convolution
BatchNorm
ReLU
Block
Convolution
BatchNorm
ReLU
AvgPool
Fully Connected
Prediction
AvgPool
Fully Connected
CNNs under Homomorphic Encryption (HE)
- Multiplication
- Addition
- Rotation
Convolution
BatchNorm
ReLU
Block
BatchNorm
Convolution
ReLU
BatchNorm
Convolution
ReLU
Polynomial
Polynomial
Polynomial
ApproximateConvolution
BatchNorm
BatchNorm
Convolution
Polynomial
Polynomial
Deep CNNs under Fully Homomorphic Encryption (FHE)
Level: number of multiplications allowed to evaluate
Level
Level
Level
- High Latency
- High Memory Footprint
Bootstrapping
Bootstrapping
- Security Requirement
- Prediction Accuracy
- Inference Latency
Deep CNNs under Fully Homomorphic Encryption (FHE)
Cryptographic Parameters
- Security Requirement
- Prediction Accuracy
- Inference Latency
Cyclotomic polynomial degree
Level
Modulus
Bootstrapping depth
Hamming weight
Deep CNNs under Fully Homomorphic Encryption (FHE)
Conv, BN, pooling, FC layers: packing
Polynomials: degree -> depth
Number of layers: ResNet20, ResNet32
Channels/kernels
Input image resolution
Polynomial CNNS
- Security Requirement
- Prediction Accuracy
- Inference Latency
Cryptographic Parameters
Cyclotomic polynomial degree
Level
Modulus
Bootstrapping depth
Hamming weight
Deep CNNs under Fully Homomorphic Encryption (FHE)
Conv, BN, pooling, FC layers: packing
Polynomials: degree -> depth
Number of layers: ResNet20, ResNet32
Channels/kernels
Input image resolution
Polynomial CNNS
- Security Requirement
- Prediction Accuracy
- Inference Latency
Cryptographic Parameters
Cyclotomic polynomial degree
Level
Modulus
Bootstrapping depth
Hamming weight

Deep CNNs under Fully Homomorphic Encryption (FHE)
Hand-crafted Design of Polynomial for CNNs under FHE
Cryptographic Parameters
Polynomials: degree -> depthPolynomial CNNS
MPCNN [1]:
[1] Lee, Eunsang, et al. "Low-complexity deep convolutional neural networks on fully homomorphic encryption using multiplexed parallel convolutions." International Conference on Machine Learning. PMLR, 2022.
- Fixed Architecture
- Periodic Bootstrapping
Convolution
BatchNorm
Bootstrapping
High-degree
Polynomial
Level
Level
Level
Level
Level
Hand-crafted Design of Polynomial for CNNs under FHE

High-degree Polynomial
Hand-crafted Design of Polynomial for CNNs under FHE

High-degree Polynomial
Low-degree Polynomial
Hand-crafted Design of Polynomial for CNNs under FHE

High-degree Polynomial
Low-degree Polynomial
Polynomial Neural Architectures
How to obtain all possible polynomial neural architectures?Key Insight
Optimize the
end-to-end polynomial neural architectureinstead of the polynomial function
Optimization of End-to-End Polynomial Neural Architecture
Poly
BN
Conv
BN
Conv
Poly
Poly
BN
Conv
BN
Conv
Poly
Poly
BN
Conv
BN
Conv
Poly
Poly 1
Poly 2
Poly 3
Poly 4
Poly 5
Poly 6
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Optimization of End-to-End Polynomial Neural Architecture


- I want a faster response
- I can wait for an accurate result
To meet different requirements in real world
AutoFHE: Automated Adaption of CNNs under FHE

Non-Arithmetic Neural Network
Polynomial Neural Nets

AutoFHE
EvoReLU: Evolutionary Mixed-Degree Polynomial Approximation of ReLU
[2] Lee, Eunsang, Joon-Woo Lee, Jong-Seon No, and Young-Sik Kim. "Minimax approximation of sign function by composite polynomial for homomorphic comparison." IEEE Transactions on Dependable and Secure Computing 19, no. 6 (2021): 3711-3727.
Forward Propagation
High-degree composite polynomial [2]:
- Pruning: DeepReDuce, SAFENet, Delphi
- Quadratic: LoLa, CryptoNets, HEMET
- High-degree approximation: MPCNN
Differentiable Evolution
EvoReLU: Evolutionary Mixed-Degree Polynomial Approximation of ReLU
Backward Propagation
- Gradient
- Gradient
- Straight-through estimated gradient
- Make training more stable
How to optimize end-to-end polynomial neural architecture?Multi-Objective evolutionary optimization
Joint Search for Layerwise EvoReLU and Bootstrapping Operations
Poly
BN
Conv
BN
Conv
Poly
Poly
BN
Conv
BN
Conv
Poly
Poly
BN
Conv
BN
Conv
Poly
EvoReLU 1
EvoReLU 2
EvoReLU 3
EvoReLU 4
EvoReLU 5
EvoReLU 6
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Boot
Joint search problem
Multi-objective optimization
- Flexible Architecture
- On-demand Bootstrapping
Multi-Objective Optimization
- Accuracy
- Latency
Single Objective

- Only generate a single solution
- Hard to tune balancing weights
- Not Pareto optimal
- Multiple solutions on the Pareto front
- No need to tune weights
- Pareto optimal
Scalarization of Multiple Objectives
Multi-Objective Optimization
Multi-Objective Optimization
Multi-Objective Optimization
Multi-Objective Optimization
Bootstrapping
Polynomial
Level
Depth
Drop 4 Levels
- Not necessarily reduce bootstrapping operations
- Directly reduce bootstrapping operations
Evolutionary Multi-Objective Optimization
population
crossover
mutation
crowding distance sorting
non-dominated sorting
Evolutionary Multi-Objective Optimization
#Layers
population size
population
crossover
mutation
crowding distance sorting
non-dominated sorting
Evolutionary Multi-Objective Optimization
population
crossover
mutation
crowding distance sorting
non-dominated sorting
Evolutionary Multi-Objective Optimization
population
crossover
mutation
crowding distance sorting
non-dominated sorting
Evolutionary Multi-Objective Optimization

population
crossover
mutation
crowding distance sorting
non-dominated sorting
Evolutionary Multi-Objective Optimization

population
crossover
mutation
crowding distance sorting
non-dominated sorting
Evolutionary Multi-Objective Optimization
population
crossover
mutation
crowding distance sorting
non-dominated sorting
one generation
search budget
How to fine-tune polynomial CNNs?Neural network adaption
trainable weights
- Inherit representation learning ability
- Adapt trainable weights to EvoReLU
Trainable Weight Adaption and Knowledge Transferring
BN
Conv
ReLU
BN
Conv
ReLU
ReLU Network
EvoReLU 1
BN
Conv
BN
Conv
EvoReLU 2
Polynomial Network
Fine-tuning objective
Experiments on encrypted CIFAR10 dataset under FHEDataset: CIFAR10
50,000 training images
10,000 test images
32x32 resolution, 10 classes
Hardware & Software
Amazon AWS, r5.24xlarge
96 CPUs, 768 GB RAM
Microsoft SEAL, 3.6
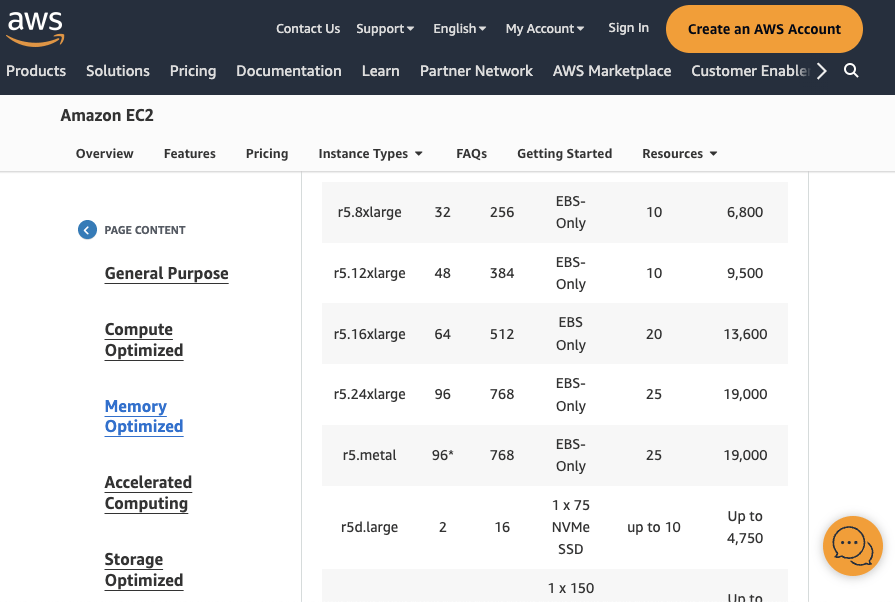
Experimental Setup
Latency and Accuracy Trade-offs under FHE

| Approach | MPCNN |
|---|---|
| Venue | ICML22 |
| Scheme | CKKS |
| Polynomial | high-degree |
| Layerwise | no |
| Strategy | approx |
| Arch | manual |
Latency and Accuracy Trade-offs under FHE

| Approach | MPCNN | AESPA |
|---|---|---|
| Venue | ICML22 | arXiv22 |
| Scheme | CKKS | CKKS |
| Polynomial | high-degree | low-degree |
| Layerwise | no | no |
| Strategy | approx | train |
| Arch | manual | manual |
Latency and Accuracy Trade-offs under FHE

| Approach | MPCNN | AESPA | REDsec |
|---|---|---|---|
| Venue | ICML22 | arXiv22 | NDSS23 |
| Scheme | CKKS | CKKS | TFHE |
| Polynomial | high-degree | low-degree | n/a |
| Layerwise | no | no | n/a |
| Strategy | approx | train | train |
| Arch | manual | manual | manual |
Latency and Accuracy Trade-offs under FHE

| Approach | MPCNN | AESPA | REDsec | AutoFHE |
|---|---|---|---|---|
| Venue | ICML22 | arXiv22 | NDSS23 | USENIX24 |
| Scheme | CKKS | CKKS | TFHE | CKKS |
| Polynomial | high-degree | low-degree | n/a | mixed |
| Layerwise | no | no | n/a | yes |
| Strategy | approx | train | train | adapt |
| Arch | manual | manual | manual | search |
Multiplicative Depth of Layerwise EvoReLU

Layerwise EvoReLU

Conclusion

- Multi-objective optimization generates Pareto-effective solutions to meet different requirements
- Joint optimization of layerwise EvoReLU and bootstrapping results in optimal polynomial neural architectures
- Adapted neural networks can inherit representation learning ability from ReLU networks
AutoFHE optimizes end-to-end polynomial neural architecture
Paper, Code & Online Slides
